Pipelines and Policies
Video
Rasa uses machine learning to make predictions about the users' intent as well
as the next best action to take. These machine learning pipelines need to be
configured in your config.yml file.
Here's a basic example of what a config.yml file might look like.
language: en
pipeline:- name: WhitespaceTokenizer- name: RegexFeaturizer- name: LexicalSyntacticFeaturizer- name: CountVectorsFeaturizer- name: CountVectorsFeaturizer analyzer: char_wb min_ngram: 1 max_ngram: 4- name: DIETClassifier epochs: 100
policies:- name: MemoizationPolicy- name: TEDPolicy max_history: 5 epochs: 10- name: RulePolicyThe config.yml file consists of two parts. The pipeline part takes care
of intent prediction and entity extraction.The policies part takes care of
selecting the next action.
Pipeline
There are different types of components that you can expect to find in a Rasa pipeline.
The main ones are:
- Tokenizers
- Featurizers
- Intent Classifiers
- Entity Extractors
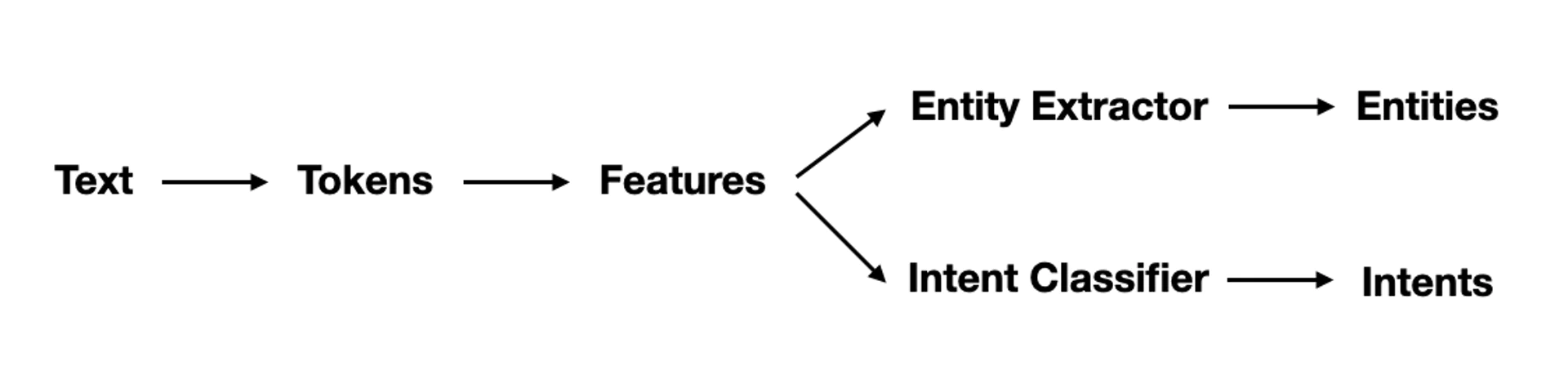
Let's discuss what each of these types of components do.
Tokenisers
The first step in a Rasa pipeline is to split an utterance into smaller chunks of text, known as tokens. This must happen before text is featurized for machine learning, which is why you'll usually have a tokenizer listed first at the start of a pipeline.

Featurizers
Once we have tokens, we can start adding numeric machine learning features. That's what featurizers do. The diagram below shows how the word "Hi" might be encoded.
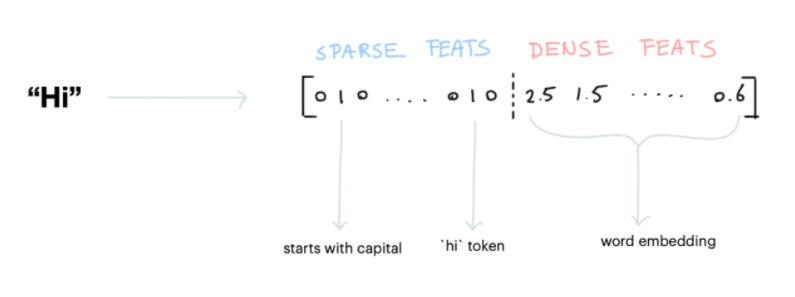
There are two types of features in Rasa:
- Sparse Features: usually generated by a CountVectorizer. We also have a LexicalSyntacticFeaturizer that generates window-based features useful for entity recognition.
- Dense Features: these consist of many pre-trained embeddings from language models. Commonly from spacy via SpaCyFeaturizers or from huggingface via LanguageModelFeaturizers. If you want these to work, you should also include an appropriate tokenizer in your pipeline.
Rasa applies these featurizers to all of the tokens but it also generates features for the entire sentence.
This is sometimes also referred to as the CLS features or the sentence features.
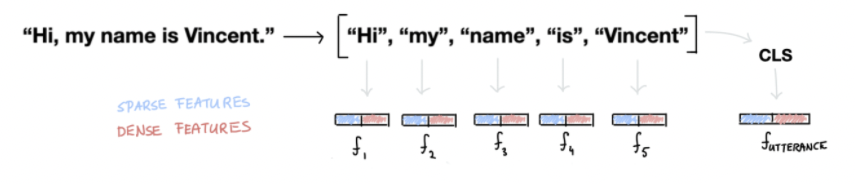
Historically, the token features were used to extract entities while the sentence features were used to detect the intent. With the introduction of Rasa's DIET algorithm this has changed, but it's good to be aware of the original design choice.
Intent Classifiers
Once we've generated features for all of the tokens and for the entire sentence, we can pass it to an intent classification model. We recommend using Rasa's DIET model which can handle both intent classification as well as entity extraction. It is also able to learn from both the token- as well as sentence features.
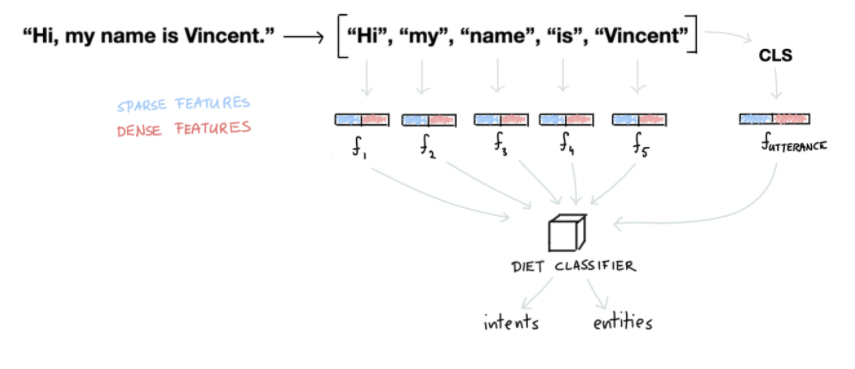
Entity Extractors
Even though DIET is capable of learning how to detect entities, we don't necessarily recommend using it for every type of entity out there. For example, entities that follow a structured pattern, like phone numbers, don't really need an algorithm to detect them. You can just handle it with a RegexEntityExtractor instead. You can also consider adding a DucklingEntityExtractor or a SpacyEntityExtractor if it fits your use-case.
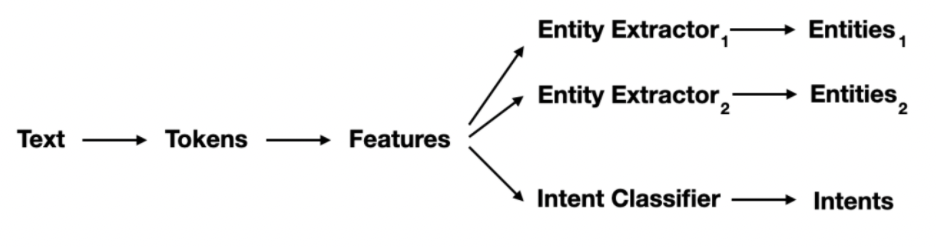
Output
The pipeline in Rasa is a system that can turn an utterance, like "Book a flight from Berlin to SF", into structured data shown below.
{ "text": "Book a flight from Berlin to SF", "intent": "book_flight", "entities": [ { "start": 19, "end": 25, "value": "Berlin", "entity": "city", "role": "departure", "extractor": "DIETClassifier", }, { "start": 29, "end": 31, "value": "San Francisco", "entity": "city", "role": "destination", "extractor": "DIETClassifier", } ]}Given that we now have our intents and entities, how can we predict the next action?
Policies
When Rasa is predicting an action, it's doesn't just look at the current intents and entities. It also looks at the conversation so far.
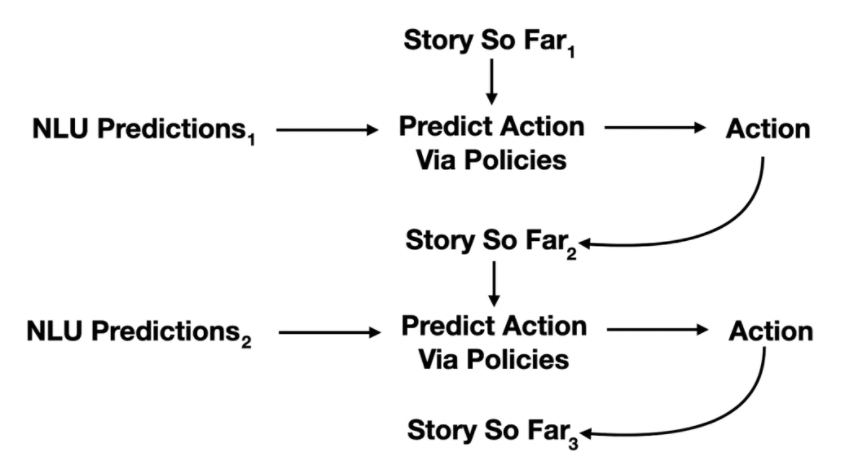
Rasa uses policies to decide which action to take at each step in a conversation. There
are three main policies that the default config.yml file starts out with:
- The RulePolicy handles conversations that match predefined rule patterns. It makes predictions based on any rules you have in your
rules.ymlfile. - The MemoizationPolicy checks if the current conversation matches any of the stories in your training data. If so, it will predict the next action from the matching stories.
- The TEDPolicy uses machine learning to predict the next best action.
These policies all make a prediction on the next action in parallel and the policy with the highest confidence determines the next action. When two policies have an equal confidence then Rasa has a priority mechanism to handle the decision. Policy priority defines how assistant makes decisions when multiple policies predict the next action with the same accuracy.
The detault priority in Rasa is:
- 6 for the
RulePolicy - 3 for the
MemoizationPolicy - 1 for the
TEDPolicy
The reason why the RulePolicy and the MemoizationPolicy have a higher priority is because
they are directly based on input from the designer. Rules and stories that have been added
are meant to be seen as examples of how conversations should go. The TEDPolicy is a policy
based on machine learning, which will try to generalise so that we can handle conversations
that aren't defined in our stories.yml and rules.yml. Although it's great to have the ability
to go beyond our own rules, we can usually trust our domain knowledge better than the statistical
approximation of a machine learning system.
RulePolicy
The RulePolicy allows you to impose strict rule-based behavior on your assistant.
policies: - name: "RulePolicy" core_fallback_threshold: 0.3 core_fallback_action_name: action_default_fallback enable_fallback_prediction: true restrict_rules: true check_for_contradictions: trueThe policy will check for rule definitions in your rules.yml file and will apply
those. You can see an example of such a rule below.
rules:- rule: Chitchat steps: - intent: chitchat - action: utter_chitchatMemoizationPolicy
The MemoizationPolicy is applied whenever the current story is similar to a
pre-existing story.
For example. If this was the story so far.
steps:- intent: greet- action: utter_greet- intent: check_balanceThen the MemoizationPolicy would be able to kick in if it was trained on the
following story.
stories:- story: check account balance steps: - intent: greet - action: utter_greet - intent: check_balance - action: utter_ask_userid - intent: inform entities:userid: “1234” - action: check_balance - intent: thanks - action: utter_goodbyeIn this case the MemoizationPolicy would predict that the utter_ask_userid is the
next action to take.
TedPolicy
The Transformer Embedding Dialogue (TED) Policy is a multi-task architecture for next action prediction. It uses features from the current conversational turn, as well as some of the past turns, to make a prediction on what to do next. If you're curious about the details it is explained in full detail in our paper and on our YouTube channel.
In general we don't recommend tweaking the hyperparameters when you're just starting out
because your first priority is to acquire a representative training set. Once you have one
though it might make sense to tune the max_history parameter of the TEDPolicy component.
policies: - name: TEDPolicy max_history: 5 epochs: 200If you have very complicated conversations where the context really matters it may
make sense to increase the max_history parameter. Note that a higher max_history
parameter may take your model longer to train.
Final Note
Rasa provides many components that you can use to build your machine learning pipelines and we've only scratched the surface of what's available in this section. In general we really advice not to prematurely optimise your system but we do want to emphasize that Rasa also supports many components for Non-English pipelines. You're also able to build your own components in Python if that's of interest.
Links
- Detailed Blogpost on Non-English tools
- Detailed Blogpost on NLU Pipelines
- Detailed Blogpost on Dialogue Policies
- Rasa Config Components Documentation
- Examples of Custom Components
Exercises
Try to answer the following questions to test your knowledge.
- What are the main building blocks of a NLU Pipeline in Rasa?
- Why do we need a priority mechanism for our policies?