Lipstick on a Pig
Unfortunately, there's a big flaw in the linear projection trick.
Video
Code
We will repeat the steps in this guide. You'll need to download two word-lists found here first.
import pathlibfrom whatlies.transformers import Pca, Umapfrom whatlies.language import SpacyLanguage, FasttextLanguage
male_word = pathlib.Path("male-words.txt").read_text().split("\n")female_word = pathlib.Path("female-words.txt").read_text().split("\n")
lang = FasttextLanguage("cc.en.300.bin")
e1 = lang[male_word].add_property("group", lambda d: "male")e2 = lang[female_word].add_property("group", lambda d: "female")
emb_debias = e1.merge(e2) | (lang['man'] - lang['woman'])We now have a debiased embeddingset emb_debias that we can use in a scikit-learn pipeline.
from sklearn.svm import SVCfrom sklearn.pipeline import Pipeline
# There is overlap in the word-lists which we remove via `set`.words = list(male_word) + list(female_word)words = list(set(words))labels = [w in male_word for w in words]
# We use our language backend as a transformer in scikit-learn.pipe = Pipeline([ ("embed", lang), ("model", SVC())])Method I: Biased Embedding, Biased Model

To run this standard model without any debiasing you can run:
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(words,
labels,
train_size=200,
random_state=42)
y_pred = pipe.fit(X_train, y_train).predict(X_test)
print(classification_report(y_pred, y_test))
This gives us the following results.
precision recall f1-score support
False 0.87 0.92 0.90 93
True 0.94 0.89 0.91 116
accuracy 0.90 209
macro avg 0.90 0.91 0.90 209
weighted avg 0.91 0.90 0.90 209
Method II: UnBiased Embedding, Biased Model
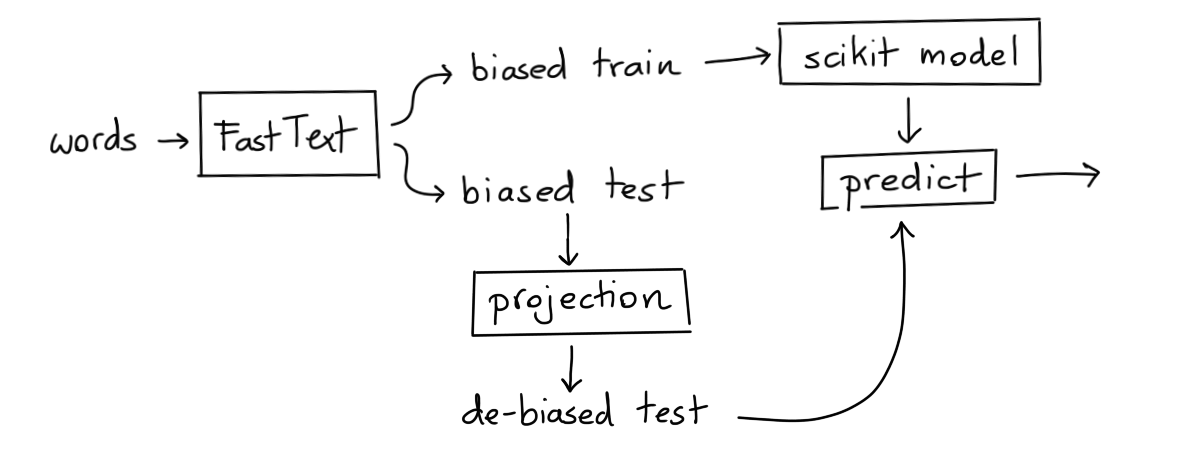
If we now apply debiasing on the vectors then one might expect the old model to no longer be able to predict the gender.
X, y = emb_debias.to_X_y('group')X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=200, random_state=42)
y_pred = pipe.steps[1][1].predict(X_test)print(classification_report(y_pred, y_test == 'male'))This gives us the following result.
precision recall f1-score support
False 0.97 0.73 0.83 131
True 0.68 0.96 0.79 78
accuracy 0.81 209
macro avg 0.82 0.84 0.81 209
weighted avg 0.86 0.81 0.82 209
Method III: UnBiased Embedding, UnBiased Model
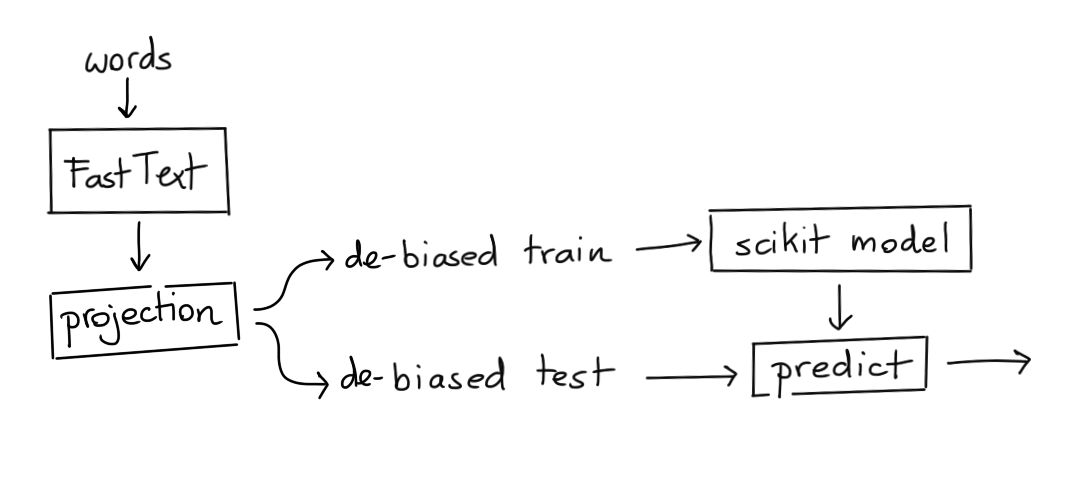
We can also try to create a model that is both trained and applied on the unbiased vectors.
y_pred = SVC().fit(X_train, y_train).predict(X_test)
print(classification_report(y_pred, y_test))This gives us the following result.
precision recall f1-score support
female 0.80 0.83 0.81 94
male 0.86 0.83 0.84 115
accuracy 0.83 209
macro avg 0.83 0.83 0.83 209
weighted avg 0.83 0.83 0.83 209
Conclusion
Cosine distance seems to suggest that we're able to remove the gender "direction" from our embeddings by using linear projections as a debiasing technique. However, if we use the debiased embeddings to predict gender it seems that we still keep plenty of predictive power.
That's why we cannot say that this deniasing technique is enough! There's plenty of reasons to remain careful and critical when applying word embeddings in practice.
Exercises
Try to answer the following questions to test your knowledge.
- Can you think of a reason why our projection trick doesn't seem to work while we do see an effect in cosine similarity?